
简介:
本软件为B站UP主@花儿不哭耗时两个月自主研发的开源低成本AI音色克隆软件(GitHub Star7.9k),他也是知名声音克隆软件Bert-vits2和RVC变声器的创始人,按照他视频里的说法,本软件一分钟就能复刻声音(并且效果比今年1月爆火的人工智能语音公司ElevenLabs的技术好很多),还有5秒极限复刻模式,用于特殊情况。我花了三天时间实测了一下效果确实很好,只需要半个小时就能训练出你想要的声音,并且1分钟的音频训练出来的相似度已经很高了,底下评论区置顶也有成功案例,因此来向大家推荐
此外,由于软件几乎每天都更新,且处于beta阶段,目前并没有版本号,因此暂时用最后一次更新的日期代表版本号,等软件作者给出明确版本号我再更新版本号
配置要求(直接借用秋月大佬的话了):
训练至少10系及以上,A卡(rx6000除外)和I卡别想训练,推理还行(cpu)
训练显存至少6G,推理至少2G
看显存:任务管理器/性能/GPU/专用GPU内存
16系显卡需要额外配置
硬要用cpu训练的劝你不要为难电脑,不如玩其他去
功能:
- 零样本文本到语音(TTS):输入 5 秒的声音样本,即刻体验文本到语音转换。
- 少样本 TTS:仅需 1 分钟的训练数据即可微调模型,提升声音相似度和真实感。
- 跨语言支持:支持与训练数据集不同语言的推理,目前支持英语、日语和中文。
- WebUI 工具:集成工具包括声音伴奏分离、自动训练集分割、中文自动语音识别(ASR)和文本标注,协助初学者创建训练数据集和 GPT/SoVITS 模型。
音频展示:
这部分请大家先去看官方的演示视频吧,体验一下这个视频最开始给我的震撼
官方演示视频地址:https://www.bilibili.com/video/BV12g4y1m7Uw
再附上我自己初步训练的日文测试音频以及B站UP和辛勤答疑员白菜工厂1145号员工训练的很不错的测试音频合集:https://wwb.lanzouq.com/iJ7Ku1mved5c
整合包下载地址:
百度网盘:https://pan.baidu.com/s/1OE5qL0KreO-ASHwm6Zl9gA?pwd=mqpi 提取码:mqpi
123云盘:https://www.123pan.com/s/5tIqVv-GVRcv.html
请大家不要将该软件用于违法用途,并且在开始之前,你必须同意并遵循使用规约,在任何音视频网站发布基于 GPT-SoVITS 项目或本整合包制作的作品时,必须在简介注明相关的说明。简介模板在下方。
本软件以MIT协议开源, 作者不对软件具备任何控制力, 使用软件者、传播软件导出的声音者自负全责.
如不认可该条款, 则不能使用或引用软件包内任何代码和文件. 详见根目录LICENSE.
软件安装使用详细教程(本人纯手打,写了几个小时,因为图片多所以显得长,其实操作起来蛮快的):
一、从度盘或者123云盘下载整合包并且用7z或者Nanazip解压,前者论坛有人发,后者能在微软官方商店下载,极其不推荐用360解压,快压等软件,可能会缺失文件


PS:要注意解压路径不能出现中文,不然出现各种报错别怪我没告诉你
二、解压完成之后运行”go-webui.bat”文件,直接双击就行,别右键用管理员身份启动,此时会出现一个黑色的控制台窗口,一定不要关闭它,关闭它程序就结束运行了

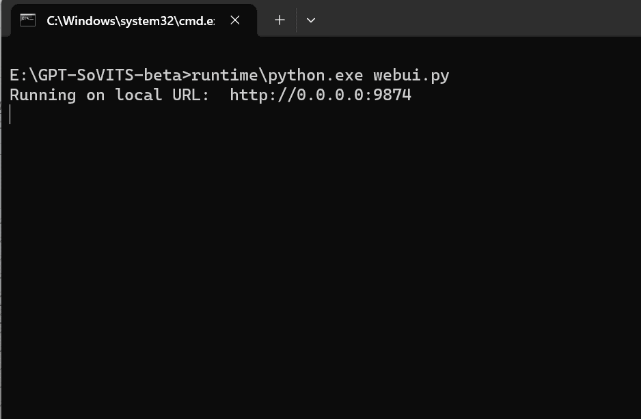
三、这个时候你的默认浏览器应该会自动弹出一个网页,如果没有弹出,那请你手动复制控制台上的网址进入,比如我的网址就是:http://0.0.0.0:9874,你可以看到网页内容是分为三个部分:0-前置数据集获取工具,1-GPT-SoVITS-TTS,2-GPT-SoVITS-变声,其中变声部分作者还在开发,所以显示还在施工中。千万不要看到这么多选项就害怕了,其实很简单,我接下来按照每个功能的序号一一讲解


这个时候你要准备一份声音素材,时长1分钟到30分钟都行,不用太长,质量好就行,并且越清晰等一下复刻的效果就越好,如果是很干净的,没有杂音的人声,那你可以直接跳过这一步,不然就需要用软件提供的UVR5来进行声音分离,这两个目前都是最强的声音分离工具之一,再或者你也可以用UVR5客户端,比网页版的效果更好,论坛已经有人发过这个客户端了,因此我不多说客户端了
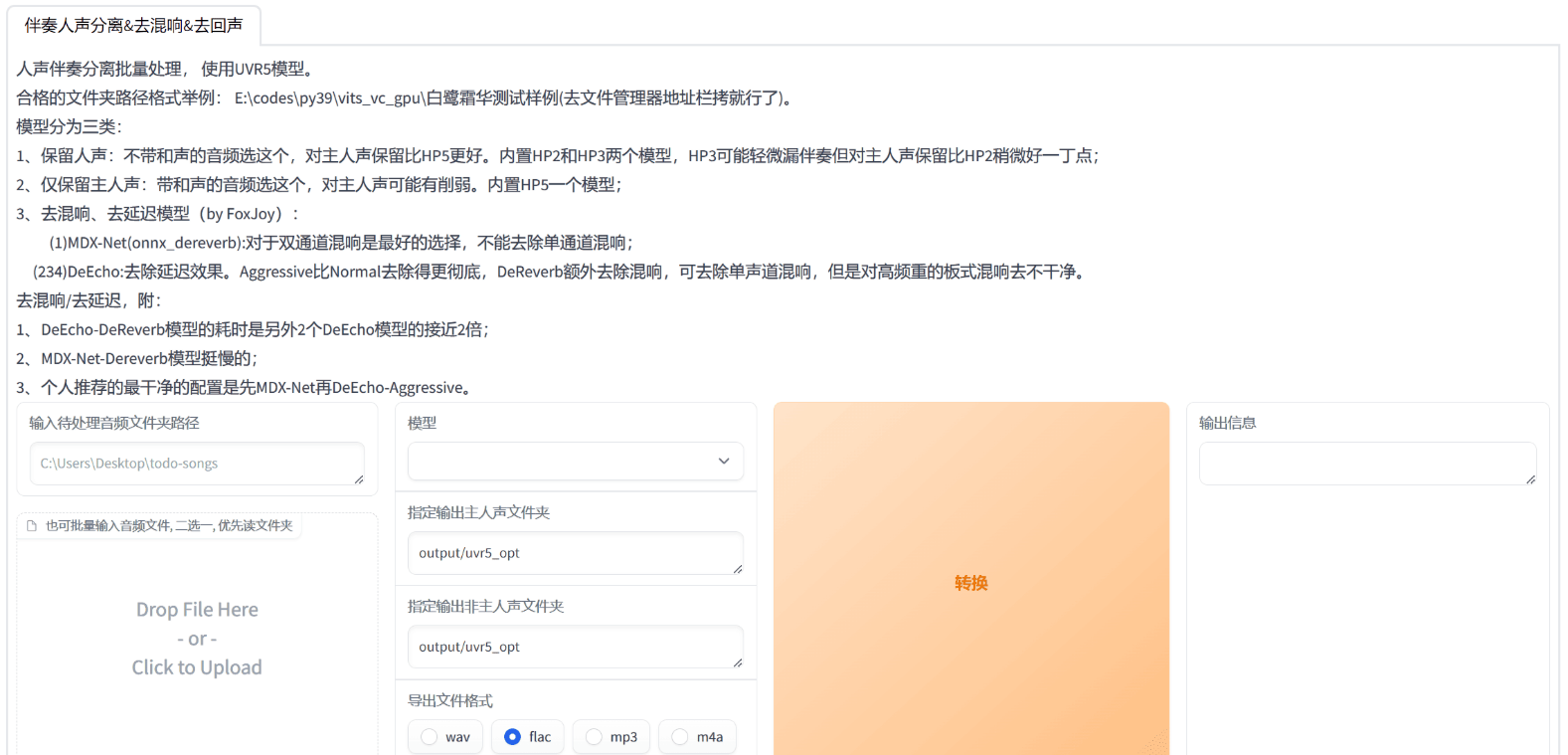
1.我们先点击“是否开启UVR5-WebUI”文字前面的框框,等待几秒,就会自己弹出来一个界面

2.在弹出来的界面中输入输入待处理音频文件夹路径,或者直接把你的音频文件拖进去,之后选择模型,这一步我们正常情况下选择HP2,如果音频文件有和声就选择HP5,导出文件格式可以选择wav或者flac,然后点击转换,速度的话3060处理40分钟音频耗时4分钟,转换完成之后还要继续处理,把分离好的人声文件再次拖进来选择“onnx_dereverb”模型来去混响,之后再把去好混响的音频文件拖进来选择“DeEcho-Aggressive”来去延迟,这样你就得到了一份处理的比较完美干净的纯人声音频文件了,这个纯人声音频文件的文件夹路径为GPT-SoVITS-betaoutputuvr5_opt
0b. 此时先取消刚刚勾上的框框,不然UVR5网页会一直占用内存,之后在红色框框里面输入你处理好或者准备好的纯人声音频文件的文件夹路径。此时如果你要训练的是中文或者英语那你直接点击开启语音分割就行,如果是日语请把每段最小时长调整为5000(日语长一点比较好,显卡好可以调到10000),之后也是点击开启语音分割,在控制台可以看到进度,这个步骤很快,切分好的文件的文件夹路径为GPT-SoVITS-betaoutputslicer_opt

0c. 此时在“批量ASR(中文only)输入文件夹路径”里面填入你的切分好的文件夹路径,点击开启离线批量ASR。如果你要训练的是日语或者英语,那么等一下就要手动转录文本打标,或者你也可以使用由另一位UP主刘悦提供的转写标注软件:https://www.bilibili.com/video/BV1LW4y1w76v,下载地址:https://pan.baidu.com/s/1OMXwY4dYiKwcYTUP223m_w?pwd=v3uc,不过这样打标出来的文件每行前面缺少一段音频文件路径比如:E:Bert-Vits2_Audio_Toolwavs/这样的,一键加上去就行,具体百度,很简单

转录标注完的文件所在的文件夹的路径为GPT-SoVITS-betaoutputasr_opt
PS:如果这一步出现报错,一般是你没设置虚拟内存,或者虚拟内存设置的不够大,请调大一点,如何设置虚拟内存请百度
0d. 1.关键来了,看好这里,这个步骤是打标,打标一定要打好,我们先在红框里面输入.list文件地址,注意是这个.list文件的地址,不是文件夹地址!然后点击“是否开启打标WebUI”前面的框框,等待一下会弹出来一个界面

2.在这个界面我们可以对于识别出来的文本进行手动的修正,你要做的就是把错误的文本改成正确的,并且一定要加上合适的标点符号,其中如果有句子出现了笑声这种不能识别成文字的语气词,先点击这个句子后面的Yes前的框框,然后点击界面上的”Delete Audio”选项,注意删除句子前请务必确保你保存了文件,保存方式为先点击界面上方的”Save File”按钮,然后点击左上方的”Submit Text”按钮,这两个都点了才算保存,只点一个不生效!

3.在修正完第一个界面的句子之后请先保存,然后再点击右上角的”Next Index”按钮到下一页继续进行修正以及删除,如果想回到上一页点击”Previous Index”按钮就行,如果想切换为黑色主题,点击界面最下方的”Dark Theme”按钮就行,全部修正并且保存完成之后就能进行下一步了,进行下一步之前,记得先把框框里面的勾去掉,修正完成的文件一般都保存在GPT-SoVITS-betaoutputasr_opt下 PS:打标过程请记住一个原则:宁缺毋滥,不要把有噪音,有笑声的片段留着不删除,这种片段极其有可能导致你训练结果很不好看
1A. 点击最开始弹出的界面上面的”1-GPT-SoVITS-TTS”进入这个步骤,首先填写模型名,一定不能填中文,填英文就好,然后填好“文本标注文件”的路径,一般为GPT-SoVITS-betaoutputasr_optxxx.list文件,之后填“训练集音频文件目录”,一般为GPT-SoVITS-betaoutputslicer_opt,都填完之后点击最下面的“一键三连”按钮,等待一小会,这时可以在控制台看到进度,显示完成之后进入下一个步骤
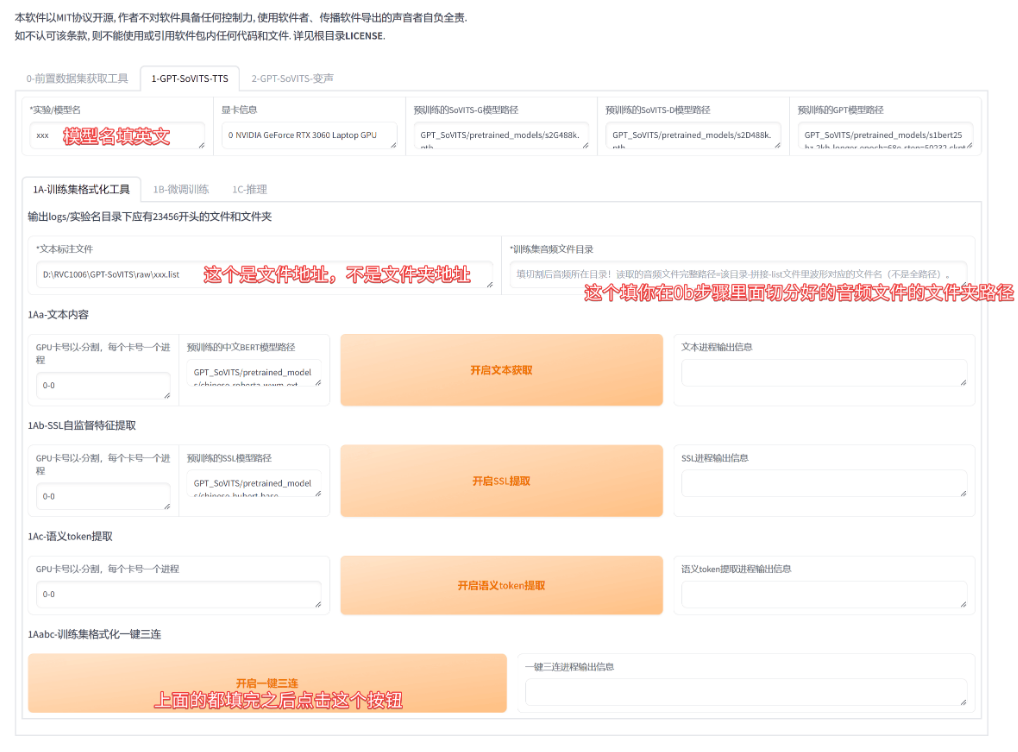
1B. 这里又要敲黑板了,这个也是重点部分,这个步骤就是训练,训练过程分为SoVITS训练和GPT训练,其中SoVITS比较慢,它的轮数不建议设置过多,多了容易出现过拟合现象,导致电音什么的,至于GPT训练,这个蛮快的,也不用训练太多轮,特别要注意的就是每张显卡的batch_size值,这个值是按照你的显卡显存/2来算的,比如6G的显存这里就推荐填3,至于怎么看显存,文章开头就告诉你了,都填好之后,先点击”开启SoVITS训练”,训练完成后再点击”开启GPT训练”,控制台可以看到进度,报错了请调低batch_size值,这个值也不是越高越好的,两次训练都完成了就进行最后一步了
PS:这里要引入一个重要概念:步数,步数=训练轮数*(你最终筛选出来的音频数量/batch_size值),这个是针对SoVITS模型来说的,训练步数不能过高,否则会出现过拟合,一般最多10000步,你筛选出来的音频越多,步数就越多,在你训练完成之后,你的模型名称结尾会有”exx_sxxxx“这种字样,”exx“中的”xx“就是代表轮数,”sxxxx“中的”xxxx“就是代表步数

1C. 1.这是最后一个步骤,这个步骤要先点击”刷新模型路径”,然后在GPT模型列表和SoVITS模型列表里面选择模型,一般就选轮数最多的,之后点击”是否开启TTS推理WebUI”的框框,等待一会弹出新的窗口

2.在弹出来的这个界面,我们要先上传参考音频,注意这个参考音频非常重要,等一会生成的音频文件的语气和语速还有音色都会最接近这个参考音频因此你要按照你等一会想生成的句子来上传参考语句,这个也是可以随时换的,效果不好换一个就行,一般第一次用你就上传一个之前切割好了的音频文件就行,这时参考文本你可以在GPT-SoVITS-betalogs模型名称2-name2text.txt里面找到

3.上传完参考音频后填写需要合成的目标文本就行,中文英语日语都能填,需要合成的语种纯中文就填中文,纯英文就填英文,纯日语就填日文,中英混合填中文,日英混合填日文,中日暂时不支持,毕竟日文和中文中都有相同的汉字并且读音不同,这里填写文本一次最好不要填太多,要少量多次,不然就有可能漏字,填完之后点击合成语音,生成速度一般都蛮快的,大概是文字内容字数的1/2秒,重要的是如果你觉得效果不太好,可以在上方的GPT和SoVITS模型列表里面切换模型,就算是相同的模型,每次生成的效果也是不一样的,如果不满意可以多试几次
使用教程就此结束,下面是分享模型的教程:
你生成的SoVITS模型就在GPT-SoVITS-betaSoVITS_weights文件夹下,你生成的GPT模型就在GPT-SoVITS-betaGPT_weights文件夹下,你可以选择这两个模型的合适的轮数,并且附上参考音频和文本进行压缩打包就能分享给别人了
关于报错,先看一下白菜工厂1145号员工写的报错合集再提问吧:https://www.yuque.com/baicaigong … 1e/pgah3gvetrdy8ryt,如果感觉有用,可以点一下文章下面的“有用”按钮,点这个可以增加推荐指数让更多人看到












暂无评论内容